
| Process of Reconstruction Across Datasets: Validation Test | |
Windographer's process of reconstruction across datasets takes data from multiple nearby datasets and 'reconstructs' each one’s missing or invalid observations of speed, speed standard deviation, direction, and temperature using the other datasets for reference. This article describes a validation test demonstrating the efficacy of that process.
In the validation exercise, we take a group of datasets measured by nearby met towers with a two-year concurrent measurement period, truncate all but one of the datasets to one year, and then reconstruct the truncated datasets back to full length. We model in Openwind the output of a hypothetical wind farm, first with the original datasets, second with the truncated datasets, and third with the reconstructed datasets. If the algorithm is beneficial, meaning if reconstructed data is better than no data, then the reconstructed datasets should produce a more accurate wind farm production estimate than do the truncated datasets.
We performed a data denial experiment using four met tower datasets (referred to as M1, M2, M3, and M4) from the High Plains region of Texas. Each covers a two-year period from April 2015 to March 2017, but we truncated M2, M3, and M4 down to a single year, and then reconstructed them back to two years using M1 for reference. The diagram below illustrates this process:
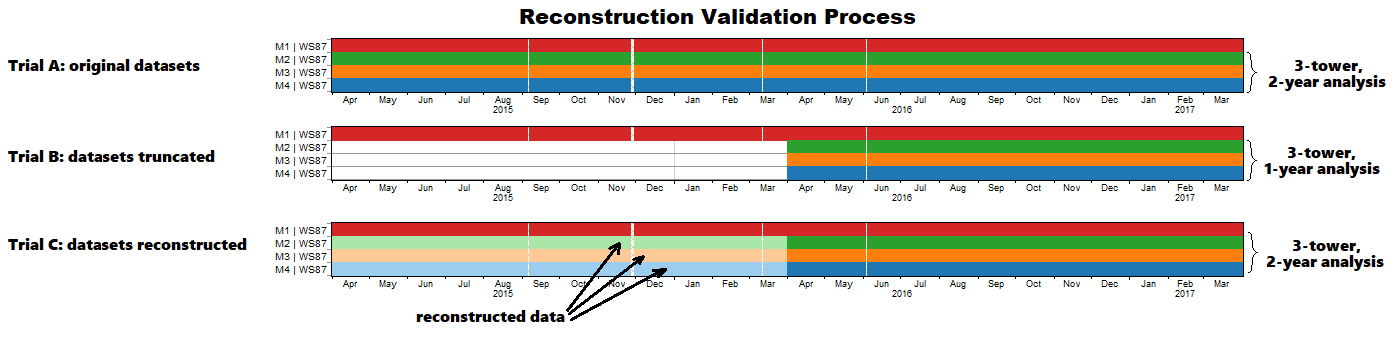
To reconstruct speed and temperature we used the ‘Total Least Squares’ MCP algorithm, subdivided into 12 direction sectors. The table below shows the correlation coefficients between the speed measurements made at each tower:
|
We modeled in Openwind the output of a hypothetical 100 MW wind farm in area of interest using the M2, M3, and M4 datasets in three separate trials: the original two-year datasets in Trial A, the truncated one-year datasets in Trial B, and the reconstructed two-year datasets in Trial C.
The table below summarizes our test results. The reconstructed (Trial C) datasets significantly outperformed the truncated (Trial B) datasets. Compared to the Trial A results, reconstruction reduced the error by two thirds. We have defined error as the relative difference in the P50 net energy production compared to Trial A.
|
The reconstructed datasets significantly outperformed the truncated datasets in our test, indicating that the process of reconstruction across datasets produces synthetic data that is accurate enough to improve simulations. In other words, the results show that reconstructed data is better than no data. This suggests that wind farm simulations can benefit from reconstruction, both to fill gaps across datasets and to extend shorter datasets to match the period of record of a longer dataset.
See also
Process of reconstruction across datasets